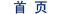








最新內容
http://www.86xian.com 發布日期:2016-06-22 中關村多媒體創意產業園 關注度:
http://www.bjmmedia.com.cn
可能大家并不是很了解知識圖譜,但是大家一定了解石油。石油不僅僅是能源,很多衍生品也都需要依賴石油。類似地,我們在進行人工智能的探索道路上,我們也需要了解其本質,或者在其基礎上衍生出各種上層的智能應用。在我個人看來,知識圖譜正是起到了這樣一個作用。
這里并沒有過多介紹公司所做的業務,而是站在一個中立的角度盡量給大家呈現知識圖譜在各領域的應用。
先介紹一些大家耳熟能詳的應用
只是大家不了解這些應用是基于知識圖譜的。
首先是“語義搜索”。因為知識圖譜這個詞最先是由谷歌在2012年提出的,作為谷歌的兩大重要技術儲備,一個是深度學習,形成了谷歌大腦;另一個就是知識圖譜,用來支撐下一代搜索和在線廣告業務。
上面的圖中,大家可以發現與傳統的搜索相比,搜索引擎開始理解用戶輸入的需求了,并對此返回各種非網頁內容信息。在圖中,對于New York(紐約州),返回各種結構化信息(在右邊),類似一種經過梳理的高質量的摘要,供大家快速了解,而非僅有包含New York作為關鍵詞的文檔內容。

接著我們再來看另一個巨頭臉譜公司的工作,它在之后利用知識圖譜技術構建興趣圖譜(interest graph),用來連接人、分享的信息等,并基于此構建了graph search。
通過上圖可以看到用戶輸入的兩個自然語言問題,一個是問喜歡哈佛大學的人(左邊),另一個訪問過哈佛大學的人,如果按照傳統的搜索做法,返回的結果會有很多重合,而事實上從返回結果我們可以看到臉譜公司可以清晰分辨這兩者的區別。
那么這里就需要做更精確的語義分析,對于這里可以識別people(詢問對象)、Harford University(大學),like/visit是動作,而like可以對應到社交網站中的點贊,而visit對應到社交網站上的簽到,這樣就能完全區分開了,更進一步,我們有了各種允許語音輸入的個人助理。
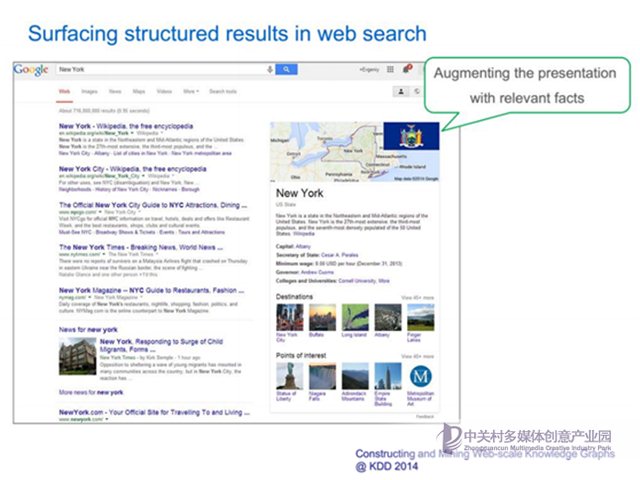
從SIRI到EVI到Google Now,這些僅僅是在交互方式上有所不同,支持自然語言自由溝通的前提是龐大的知識庫和基于知識庫的各種服務—即知識圖譜,此外,大家都知道IBM近年來一直在推動認知智能和智慧地球的理念。
IBM在2011年研發了Watson問答系統,參加了Jeopardy!(危險邊緣)電視節目,類似國內的一站到底和開心詞典,并打敗人類冠軍。很有幸,我參與了2年的Watson系統研發,這對后面的經歷以及目前公司的技術選型有比較大的影響。
剛剛舉了一些例子,我們總結一下知識圖譜會帶來的好處
這個對于大數據來說,其實就是全數據的概念。而對于人工智能來說,其實就是將原本沒有聯系的數據連通,將離散的數據整合在一起,從而提供更有價值的決策支持。而這里的副標題其實更進一步針對B端市場,我們強調了外部數據和內部數據整合的意義和價值。
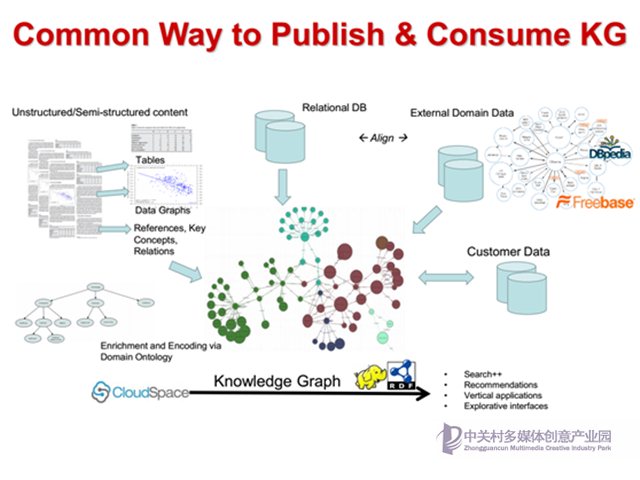
這是一個通用的知識圖譜的框架,我們可以看到知識圖譜不是空中樓閣,而是基于現有數據的再加工,包括關系數據庫中的結構化數據、文本或XML中的非結構化或半結構化數據、客戶數據、領域本體知識以及外部知識,通過各種數據挖掘、信息抽取和知識融合技術形成一個統一的全局的知識庫。
注意這里的全局知識庫并非中心管理,而是一個邏輯上的全局(即數據統一,語義清晰)。
那么知識圖譜能做什么呢?也就是上面提到的那些大家熟悉的應用(搜索、推薦、以及在后面會提到的各種垂直應用)。
知識圖譜在生命科學中的應用
第一個應用是藥物發現
大家都知道,醫藥公司往往花費10億美元甚至更高來研發新藥,如何縮短新藥研制周期,降低研發成本是大家所關注的。

這里首先大家可以了解一下歐盟第7框架下的一個重大項目,稱之為開放藥品平臺Open Phacts,這個項目吸引了輝瑞和諾華制藥等巨頭參與。利用來自實驗室的理化數據、各種期刊文獻中的研究成果、以及各種開放數據(其中比較有名的包括Clinical Trials.org,美國開放數據中的臨床實驗數據)來加速藥物研制中的分子篩選工作。
具體來說,我們看一個例子:

大家都知道,阿爾茲海默癥也就是老年癡呆癥是世界難題。這里給出了3個觀察:藥物研發經常需要去找藥物靶點,而藥物靶點中大家關注的是其中豐富的信號轉導通路,更具體來說即對于化學治療起作用的蛋白。同時我們知道老年癡呆癥患者的CA1錐形神經元是損壞的,那么我們在做基因篩選的時候就會發問:能否找到存在于上述信號轉導通路中,且被包含在上述神經元的候選基因呢?

更具體來說,我們將其轉換為一個復雜的查詢,大家不用糾結這個查詢的格式,這是一個圖查詢,是圖譜對應的標準格式,稱為SPARQL。這個查詢一共跨越了4個數據源,錐形神經元在Mesh(美國NIH發布的標準術語)中Entrez Gene是一個知名的基因知識庫。
而GO(基因本體)包含信號轉導,同時可以在圖中看到有兩個橙色部分的查詢,需要依賴去做知識推理。知識推理就是希望通過邏輯和統計的方法從顯式的數據中得到隱含的知識。
比如這里,是要做一個傳遞閉包的推理,因為part of (部分)是一個可以傳遞的,A part of B, B part of C可以推出A part of C。這樣得到的候選基因能讓醫學研究人員更加專注,省去了大量用機器(即使是華大基因)去篩選基因的耗費。
剛剛我們也提到了Watson,隨著Watson取得巨大成功,IBM成立了Watson group(事業部),對各種行業進行認知攻破。第一個就是醫療方面。
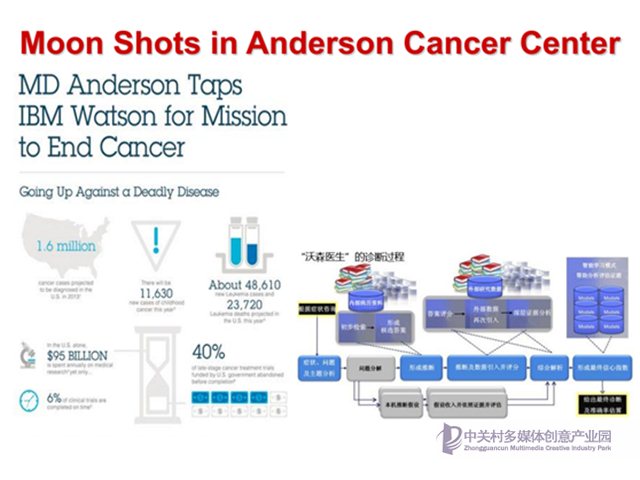
這是在安德森癌癥中心的實驗,我們知道Anderson癌癥中心是全國最有名的癌癥中心。IBM稱這個項目為登月計劃(moon shot),這里通過整合大量醫療文獻和書籍以及各種EMR(電子病歷)來獲取海量高質量的醫療知識,并基于這些知識面對醫護人員提供輔助臨床決策和用藥安全等方面的應用,并取得了巨大成功。
知識圖譜在農業中的應用
大家都知道我國是農業大國,但是我們的農業又多是基于小作坊,靠手工或看天工作的階段。

當然整個亞洲其實和美國這種大農場主統一管理的方式很不同,也存在各種資源利用率低的現狀,我們發現有超過50%存在農藥過分灌溉或缺乏灌溉的情況。
大量的資料是很分散的,而且存放在各種格式中,而農民們非常迫切希望有人來指導他們更好地進行灌溉和解決蟲害,那么這個時候的關鍵就是使得各種農業相關的知識可被這些農民朋友訪問到。
這里我們以柑橘知識為例,我們發現傳統的關系數據庫模式對于這種復雜或多變的領域是不可行的,因為我們無法實現定義所有可能的知識點(用于構建關鍵數據庫模式)。所以我們需要一種更加靈活的知識表示模型來管理,這個時候知識圖譜就能起到很好的作用。
如果大家對知識圖譜還比較陌生的話,可以看到這里貼出的可視化圖,即根據上述施肥問答信息抽取構建的圖譜片段。類似的,我們可以用各種抽取挖掘技術從各種多源異構數據中獲取相應的知識,并統一用圖譜進行表示,從而形成一個完整的知識庫。
這里以Excel表或CSV文件為例,我們可以通過構建wrapper將其列映射為圖模式,而將下面的記錄(每一行)映射為對應的符合模式的圖數據,并與之前從問答知識數據中獲取的圖譜進行關聯整合。
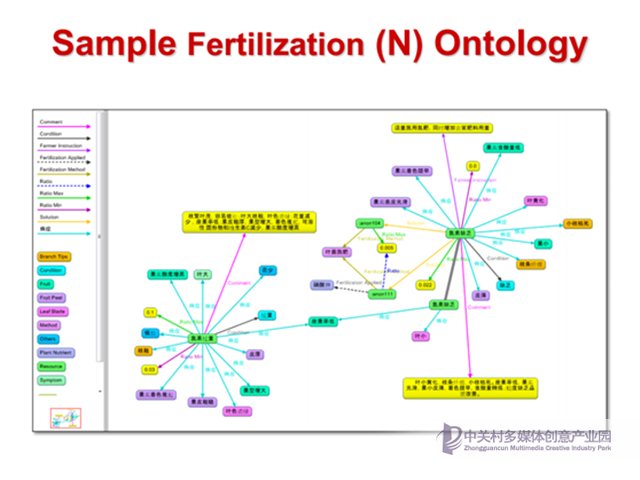
這是一個整合之后的化肥本體知識。
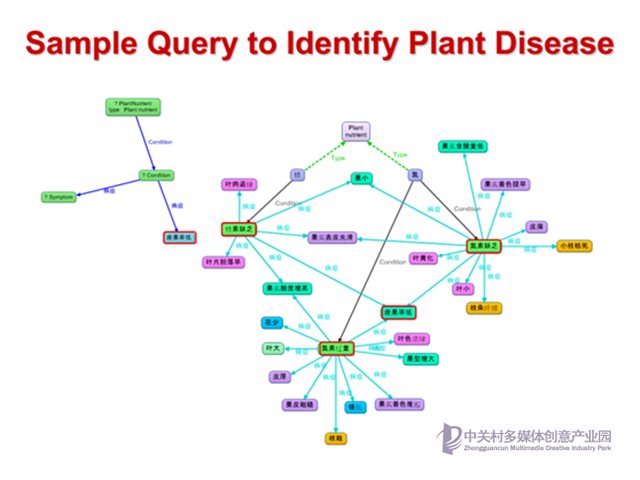
對于這個知識庫,我們可以通過SPARQL查詢(可以可視化為圖譜)來利用知識庫,這里的例子是查詢癥狀是座果率低的植物和其他相關癥狀。
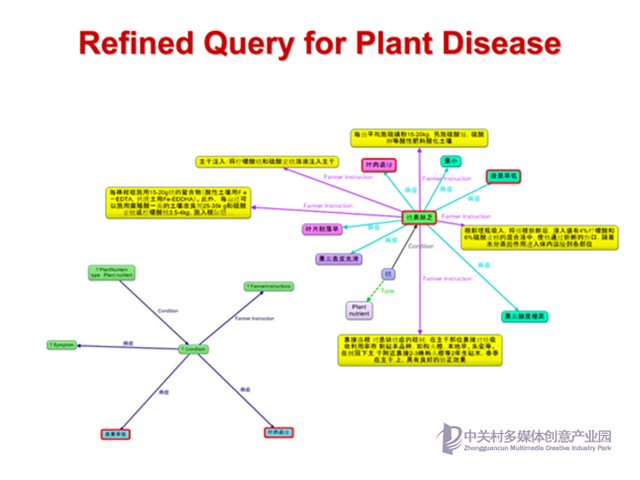
圖查詢類似圖譜數據,非常靈活,可以方便地進行變化,通過增刪節點和邊來實現,從而增加條件或放松條件。
這是一個完整的例子,即缺乏氮素的植物以及植物灌溉知識。通過例子可以看出,我們可以通過圖譜關聯到圖片信息,這樣形成了多媒體知識圖譜,而這些病變的圖片信息相比專業知識更加直觀,也更方便農民使用。
這里總結了,在農業方面知識的影響和作用,我們可以刻畫作物知識、土壤、肥料知識、疾病知識和天氣知識等。

通過知識圖譜,我們可以將傳統的農業轉換為精準農業(precision agriculture)。
知識圖譜在電信行業客服中的應用
Amdocs是美國最大的第三方賬單審計和客服中心,AT&T, Verizon和Sprint等都是他的客戶,美國的電信市場很早就飽和了,所以各大運營商均沒有很多新客戶可以爭取,那么維護好老客戶就非常重要。

這是一個案例,大家有時間看看,其原則就是希望對于信用好的用戶能前瞻性地了解他的需求,并在他打電話來反映情況的時候(抱怨或詢問信息等),可以預先判斷他需要什么,并幫其解決,從而減少溝通次數和溝通時長。
為了做到這一點,系統需要判斷用戶的信用等級。并根據用戶的當前消費情況和各種動作來自動化判斷其可能的行為。
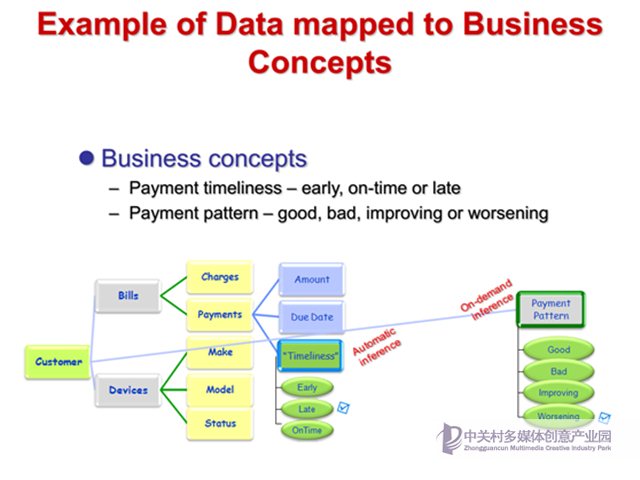
這是一個簡單的電信行業使用的數據分類和商業概念歸類,包含設備、賬單、支付等一系列重要知識。
通過上述概念得到的各種數據包括結構化,也包括流數據進行的各種數據映射和轉換,類似的,也是形成統一的圖譜進行管理。這個還包括趨勢、時間、地理還有消費模式等很多信息。通過各種數據源進行數據的整合,形成統一的知識,并配合業務規則和貝葉斯網絡來形成決策引擎,從而對用戶的信用和各種行為結果預測起到作用。
最終達到的效果就是個性化前瞻性的客戶關懷。
知識圖譜在媒體發布中的應用
最早使用知識圖譜的是英國廣播電臺,之前傳得很火的新聞自動寫作機器人也利用了知識圖譜。
舉個例子,針對2012年倫敦奧運會,很多對象的跟蹤報道由專人負責,然后通過圖譜將各種零散的信息關聯在一起,從而形成一個完整頁面。

這是通過得到的一個聚合的頁面(一個德國的游泳運動員),不僅呈現比賽新聞信息,也包含這個運動員的方方面面。
知識圖譜在金融方面的應用
金融方面是僅次于醫療(知識圖譜應用最廣泛的領域)。
先介紹一個我之前參與的國外的例子,是針對荷蘭的案例。荷蘭的法律導致破產是不用負責的,所以很多人鉆這個空子來構建團伙進行倒賣,最后將其中的一些公司申請破產導致非法免費獲得很多資源。
這一點,荷蘭政府非常頭疼,希望找到幕后組織,從而避免很多損失。
類似的,現在的問題(尤其是大數據情況下),各個部門和組織的數據非常分散,導致各個部門沒有辦法得到完整的信息來進行對上述團伙的判斷。而傳統的數據集成方法需要依賴非常有經驗的專家對這些數據庫進行手工集成,這大大增加了工作量和處理周期。
所以這里我們又將引入知識圖譜,進行有效的去中心化的高效知識融合。
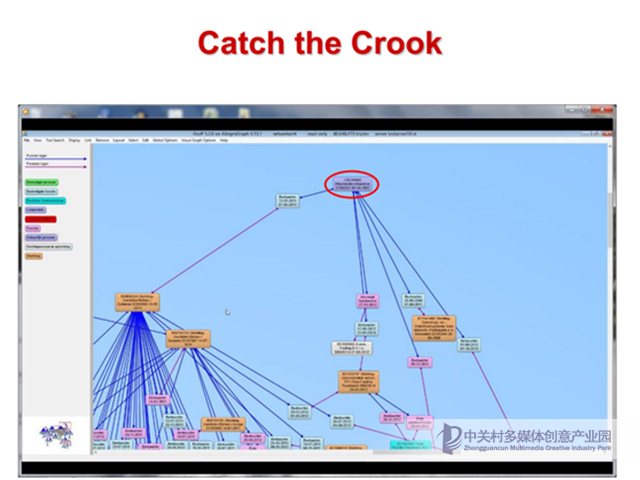
這是一個示例,和農業中的方案類似,不過使用了一個Hadoop PIG腳本來控制轉換過程,之后我們將通過圖可視化來發現這樣的團伙。這個可視化的圖中可以看到粉色的公司、橙色的機構和紅色的破產的公司。
當我們將這張圖進行縮放之后,可以發現這里一些有趣的模式,所有的紅色破產企業都關聯到圖中圈定的公司,那么這個公司就有可能是指使這些破產行為的最終元兇。政府相關部門就可以對其進行深入的調查,這樣使得原本大海撈針的搜索變得很有針對性。
還有更多的例子:
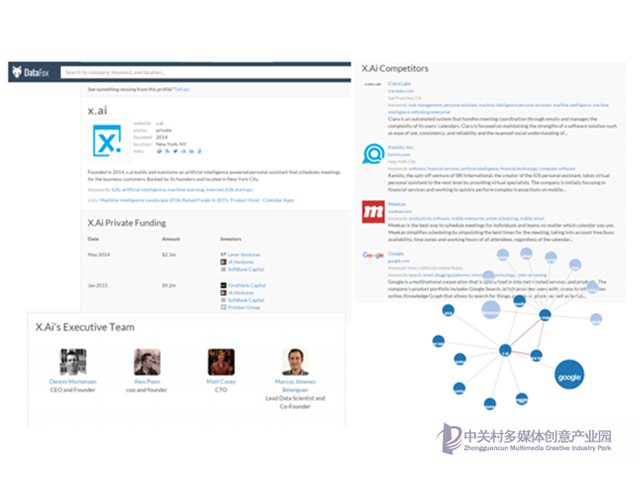
國外有Datafox和Spiderbook,國內有通聯數據等。
他們通過從互聯網上抽取各種公司(主要是上市公司)的數據,包括產品、高管、公司供應鏈關系、競爭對手關系等,整合為統一的圖譜從而幫助企業或投資機構進行全網數據的關聯分析,影響傳播和一些預測。
最成功的例子包括福島爆炸對豐田汽車的股價影響。
知識圖譜在政府中的應用
這里就不得不介紹最近非常紅火的美國的獨角獸Palantir。
Palantir應該是美國最早在政府領域使用知識圖譜技術的公司,幫助美國政府成功定位到了本拉登的位置等。
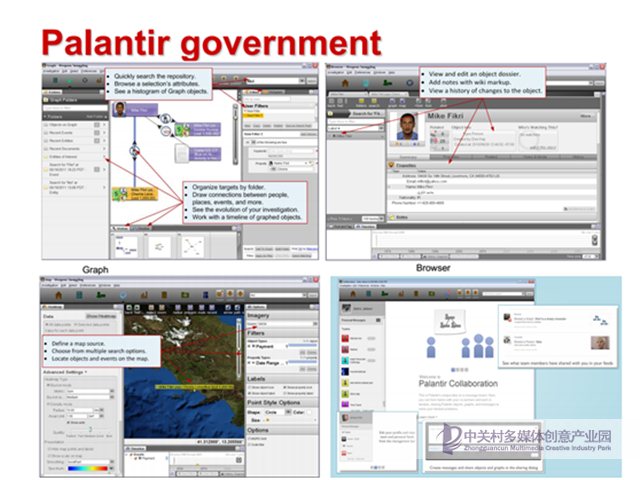
其界面也包含各種圖譜瀏覽、搜索、建模等工具,類似的,將不同來源不同格式的數據進行建模整合,來得到全面分析和挖掘的可能。
總結
知識圖譜能做到的就是讓知識可被用戶訪問到(搜索),可被查詢(問答),可被支持行動(決策)。

當然知識圖譜的構建和應用具有很大的技術難度,這里需要使用自然語言處理技術、數據庫技術和語義推理技術等多重支持。
(來源:虎嗅網)
 |  |
 |  |
